
 Google, yapay zeka modellerinin en büyük darboğazlarından biri olan bellek tüketimi ve işlem maliyetini kökten değiştirebilecek yeni bir teknolojiyi duyurdu. “TurboQuant” adı verilen sıkıştırma algoritması, büyük dil modelleri başta olmak üzere modern AI sistemlerini çok daha küçük, hızlı ve verimli hale getirmeyi hedefliyor.
Google, yapay zeka modellerinin en büyük darboğazlarından biri olan bellek tüketimi ve işlem maliyetini kökten değiştirebilecek yeni bir teknolojiyi duyurdu. “TurboQuant” adı verilen sıkıştırma algoritması, büyük dil modelleri başta olmak üzere modern AI sistemlerini çok daha küçük, hızlı ve verimli hale getirmeyi hedefliyor.
Şirketin araştırma blogunda paylaşılan bilgilere göre TurboQuant, model boyutunu ciddi şekilde küçültürken dikkat çekici bir şekilde doğruluk kaybı olmadan çalışabiliyor. Bu özellik, bugüne kadar yapay zeka optimizasyonunda karşılaşılan en büyük sorunlardan birine doğrudan çözüm sunuyor.
TurboQuant’ın odak noktası, “anahtar-değer önbelleği” (key-value cache). Google bunu, modelin tekrar hesaplama yapmamak için önemli bilgileri sakladığı bir tür dijital kopya kağıdına benzetiyor. Çünkü büyük dil modelleri aslında bilgiyi gerçekten bilmiyor, bunun yerine, anlamları temsil eden vektörler üzerinden çalışıyor. Bu vektörler, metni sayısallaştırarak anlam ilişkilerini kuruyor. İki vektör birbirine ne kadar yakınsa, kavramsal olarak da o kadar benzer demek.



Ancak bu vektörler oldukça yüksek boyutlular ve yüzlerce hatta binlerce parametre içerebiliyorlar. Bu da hem bellekte büyük yer kaplamalarına hem de performansın düşmesine neden oluyor. Bu sorunu çözmek için geliştiriciler genellikle “quantization” (nicemleme) adı verilen yöntemlerle veriyi daha düşük hassasiyetle işliyor. Fakat bunun dezavantajı, model çıktılarının kalitesinin düşmesi. TurboQuant ise Google’ın ilk testlerine göre kaliteyi bozmadan 6 kat daha az bellek kullanımı ve 8 kat daha yüksek performans sağlayabiliyor.
TurboQuant nasıl çalışıyor?
TurboQuant iki aşamalı bir süreçten oluşuyor. İlk adımda “PolarQuant” adı verilen bir sistem devreye giriyor. Normalde yapay zeka vektörleri XYZ (kartezyen) koordinatlarıyla ifade edilirken, PolarQuant bunları kutupsal koordinatlara dönüştürüyor. Böylece her vektör yalnızca iki bilgiyle temsil ediliyor: yarıçap (verinin gücü) ve açı (verinin anlam yönü).
Google bunu şöyle örneklendiriyor: Geleneksel yöntem “3 blok doğuya, 4 blok kuzeye git” demek gibiyken, yeni yöntem “37 derece açıyla 5 blok git” şeklinde daha kısa ve verimli bir ifade sunuyor. Bu da hem veri boyutunu küçültüyor hem de hesaplama yükünü azaltıyor.
İkinci aşamada ise oluşabilecek küçük hatalar düzeltiliyor. PolarQuant veriyi sıkıştırırken bazı sapmalar yaratabiliyor. Bunu düzeltmek için “Quantized Johnson-Lindenstrauss (QJL)” yöntemi kullanılıyor. Bu teknik, her vektörü yalnızca tek bir bit (+1 veya -1) ile temsil ederek hata düzeltme katmanı ekliyor ve önemli ilişkileri koruyor. Sonuç olarak modelin dikkat (attention) hesaplamaları daha doğru hale geliyor.
İddialı performans değerleri
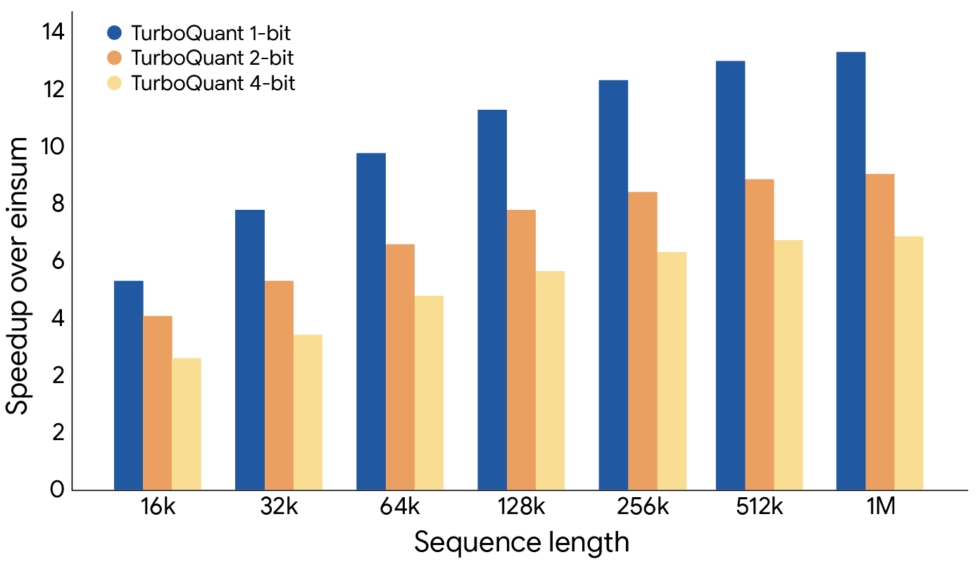 Google, TurboQuant’ı Gemma ve Mistral gibi açık modeller üzerinde test ettiğini söylüyor. TurboQuant, iddiaya göre tüm testlerde çıktı kalitesini koruyarak kusursuz sonuçlar elde ederken, anahtar-değer önbelleğinin bellek kullanımını 6 kat azaltmayı başardı. Algoritma, ek bir eğitim gerektirmeden önbelleği sadece 3 bit seviyesine kadar sıkıştırabiliyor; bu da mevcut modellere doğrudan uygulanabileceği anlamına geliyor. Ayrıca 4-bit TurboQuant ile dikkat hesaplamaları, Nvidia H100 üzerinde 32-bit sıkıştırılmamış anahtarlara kıyasla 8 kat daha hızlı gerçekleştirilebiliyor.
Google, TurboQuant’ı Gemma ve Mistral gibi açık modeller üzerinde test ettiğini söylüyor. TurboQuant, iddiaya göre tüm testlerde çıktı kalitesini koruyarak kusursuz sonuçlar elde ederken, anahtar-değer önbelleğinin bellek kullanımını 6 kat azaltmayı başardı. Algoritma, ek bir eğitim gerektirmeden önbelleği sadece 3 bit seviyesine kadar sıkıştırabiliyor; bu da mevcut modellere doğrudan uygulanabileceği anlamına geliyor. Ayrıca 4-bit TurboQuant ile dikkat hesaplamaları, Nvidia H100 üzerinde 32-bit sıkıştırılmamış anahtarlara kıyasla 8 kat daha hızlı gerçekleştirilebiliyor. TurboQuant gibi teknolojiler, yapay zeka modellerinin çalıştırma maliyetini düşürebilir ve daha az bellekle daha güçlü sistemler oluşturulmasını sağlayabilir. Özellikle mobil cihazlar için bu gelişme büyük önem taşıyor. Akıllı telefonların donanım sınırları düşünüldüğünde, TurboQuant gibi sıkıştırma teknikleri sayesinde veriler buluta gönderilmeden cihaz üzerinde daha kaliteli yapay zeka çıktıları mümkün olabilir.
Kaynak : https://www.donanimhaber.com/google-dan-yapay-zekada-devrim-turboquant-ile-yuksek-sikistirma–203657

















